Say Penis Architecture
This is a discussion of the stack that makes the Say Penis app. I'm confindent that this is a reliable, scalable and debuggable architecture. However, most of the choices between leading technologies were made based on using technology with which I am familiar.
Spoiler alert: I used to work at Amazon.
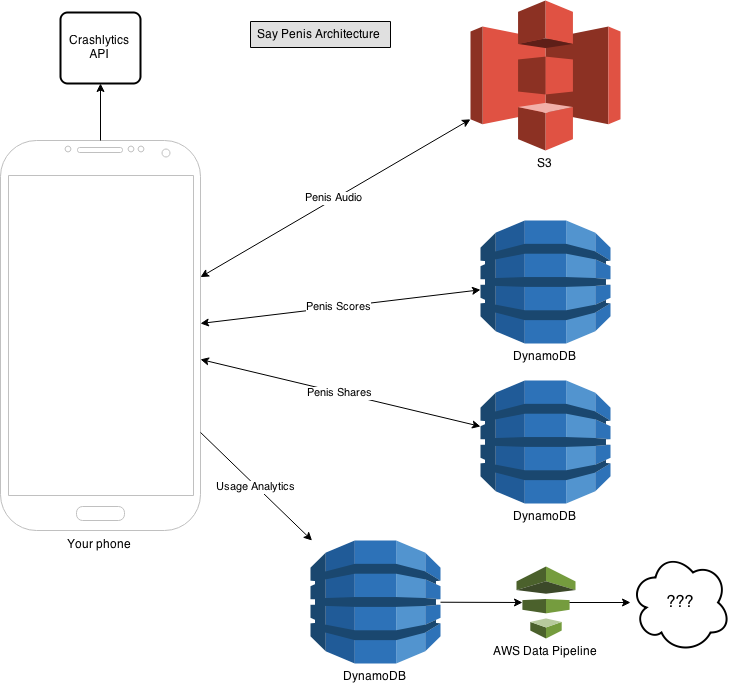
The stack is dead simple. Your phone reads and writes directly to DynamoDB tables for penis scores and whenever you share or try to view a penis shared with you. Penis audio is stored in S3 and referenced via a url stored with the penis score.
Unexpected crashes are handled by the Crashlytics and usage analytics is also stored in DynamoDB and can be processed via AWS Data Pipelines. I'll get into Crashlytics and UA more later.
Question 1: Why no central server?A central server would make writing future clients (such as iOS or web) easier since all the client applications could hit the same REST endpoint. However, when I'm doing a side project like this, I don't want to deal with a single point of failure. If one person's phone hit and edge case I haven't thought over, who cares? Only that person. Furthermore, when that does happen, Crashlytics opens an issue for me to track fixing that bug.
If that happens server side and my service starts crashing its bad news bears for everyone. That single point of failure is the kind of thing that keeps my up at night.
A relevant anecdote is that for a while, when I thought Google had modified part of the voice API I rely on I actually wrote a central server running on AWS Elasticbeanstalk based off of CMUSphinx that handled all the scoring and writing to dynamo logic. In fact, the top scores page gets its scores by hitting that API. I leave that service up in read-only mode since it keeps the global top scores in memory for fast access.
Question 2: Why AWS and not Google's cloud?The first (and main reason) is that I'm significantly more familiar AWS products and very comfortable spinning up new stack.
Secondly, I took this awesome edX course and got $1000 in AWS credit. During development, Say Penis has cost me about $40 in AWS credit so having a bank roll is nice.
Third, integrating android with AWS is easier than doing it with Google's tools in my experience. I'm not an expert in Google Cloud Endpoints by any means but as a backend dev I feel more comfortable (and move much faster) throwing up a Jersey service on Elasticbeanstalk. Likewise, I feel more comfortable talking directly to dynamo than learning Google whatever-awesome-nosql-store-they-have. Just personal preference.
Question 3: What's the deal with Crashlytics and Usage Analytics?If you are writing apps and not using Crashlytics or something similar, you're fuckin' up. It catches exceptions and gives you all the awesome juicey details about wtf happened to you app. I set it up via the Fabric Eclipse plugin which takes about 20 seconds to do. Seriously, try it.
Later I'll write another post later about other awesome tools I've been trying out for this project.
As for Usage Analytics, I know a lot of companies provide awesome services here (even Amazon has one I could add to my chart). However, they didn't meet my needs so I wrote my own.
Most existing UA products value seems to come from the pretty pictures they draw for you and are mildly painful to install or cost money.
What I wanted was a super easy way to dump simple actions into a place that I could go look at them later. I don't need awesome, constantly refreshing graphs showing my perf and click-thru numbers. All I want is to go back later and nerd out over some data.
My android usage analytics library allows dumping rows directly into dynamo which a couple customizable columns for payload. This is perfect because at whatever point I decide to throw my data in an elasticsearch cluster or some other fancy-pants data analysis tool, I can simply run a AWS Datapipeline, dump my table and much around with it.